Research in speech recognition for English and Chinese has shown impressive progress recently. However the only product I found for Amharic was Google’s cloud service. It supports Amharic and works surprisingly well. Nevertheless, it would be wrong to conclude the problem had been solved as we don’t know Google’s methodology and evaluation of it. On top of that, their work is proprietary. There needs to be an open research to speed up progress and make it open for wider use.
This post explains how I applied Deep Recurrent Network to train a speech recognizer for Amharic. I’ll share details of my approach, dataset, and results. Knowledge of Deep Learning and RNNs is beneficial although not necessary. All my work is available on github.
The challenge
First, it’s helpful to understand what we are up against. Research in speech recognition started way back in the 1950s. Why did it take too long? It turns out there is variation in how we pronounce words which makes recognition tricky. Let’s see an example. Here is a recording of the same speaker saying the same word.
Let us now plot the audio signals. These are basically one dimensional array of numbers. We see the two clips have different signals.
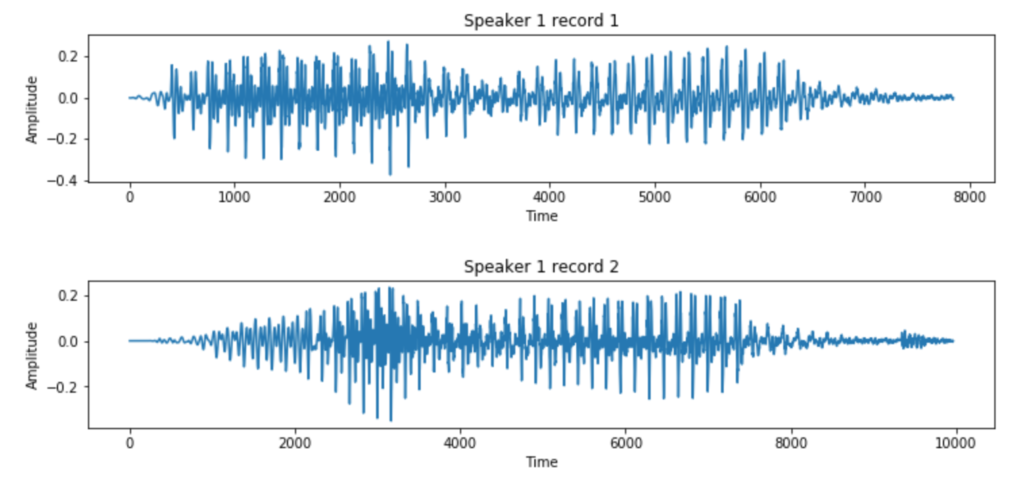
And here is a second speaker, this time female, saying the same word.
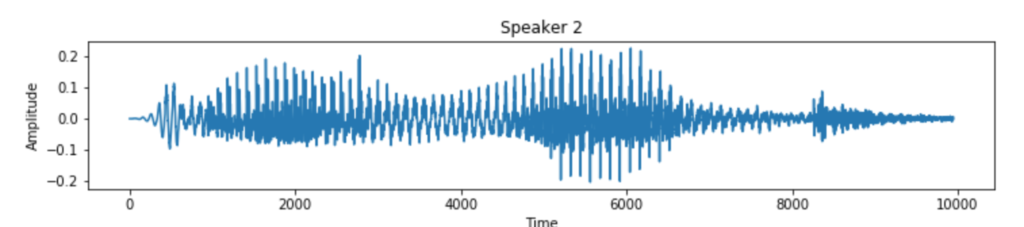
The second speaker’s recording looks even different from that of the first. To make the problem worse, there are different accents, some people speak fast while others a bit more slowly, our pitch varies, there can be background noise, and so forth. If the speaker is viewable, we humans pay attention to mouth movements and gestures to aid the listening process. We also consider context – if we didn’t hear a word very well, we fill in the gap by considering what the speaker said before and after.
Data
Data for Amharic speech recognition is extremely difficult to come by. There is plenty of audio data in Amharic but very little transcription of it. Luckily, a friend pointed me to Getalp. They prepared about 10k audio clips totalling 20 hours of speech. Each clip is a few seconds long and comes with its transcription. There are a few hundred separate clips for validation purposes as well.
Features
Key to any machine learning method is extracting features from data. Features represent data and serve as input to the learner. Speech recognition methods derive features from audio, such as Spectrogram or Mel Frequency Cepstrum (MFCC). Audio is split into small blocks, such as 10 milliseconds, and each block is broken into its constituent frequencies. A good example is musical chords. Listen to the following audio.
Three notes are played separately and then all three are played simultaneously. The last piece of sound, called a chord, is similar to what we hear in speech.
I chose to use MFCC over Spectrogram because it produces fewer number of features. Spectrogram can work even better than MFCC as it gives more features. The downside is it needs more data and longer time to train. What does MFCC look like? Let’s take a few seconds of audio clip and plot it’s MFCC features. The result is shown below. Time is on the Y axis. Each horizontal line represents a short audio clip of 10 ms duration. The 13 columns (0-12) represent what’s known as MFCC coefficients in signal processing. Here we simply refer to them as MFCC features. Colors are intensities. Since I chose to use 13 coefficients, each 10ms audio is represented by an array of 13 numbers.
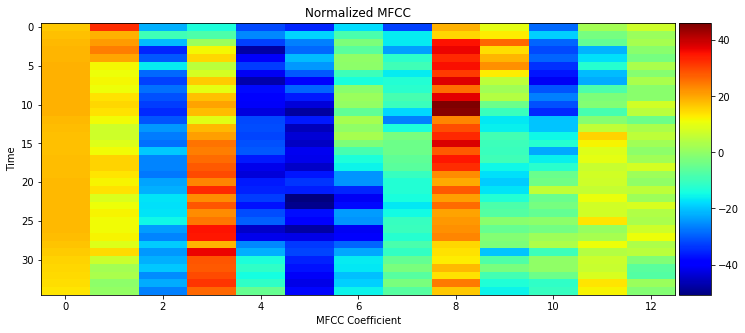
You can read further on MFCC and the reason for choosing 13. I suggest you don’t spend much time on though, because Deep Learning researchers are interested in having the network learn features by itself instead of spending time researching on how to pre-process data for it.
Deep Learning and Recurrent Neural Networks
The strength of neural network based solutions lies in the fact that they can be used as generic learning methods to any problem. It has been proven by their application to self driving cars, image recognition, healthcare, and machine translation to name a few. I used Deep Learning (DL) and Recurrent Neural Networks (RNN) because it has shown excellent results and tech companies including Google, Amazon and Baidu use DL for speech recognition.
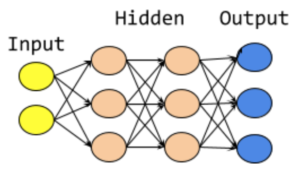
The core idea is to have a network of interconnected nodes (also known as Neural Networks) where each node computes a a function and passes information to the nodes next to it. Every node computes it’s output using the function it was configured to use, and some parameters. The process of learning updates these parameters. The function itself will not change. Initially the parameters are randomly initialized. Then training data is passed through the network, making small improvements to the parameters on every step.
If it all looks like magic, you are not alone! In fact, even leading researchers in the field experiment with different functions and network layouts to see which one works best. There are some well understood functions and network architectures. In case of speech recognition, Recurrent Neural Network (RNN) are used as their output depends not just on the current set of inputs, but on previous inputs too. It’s crucial in speech recognition because predicting what has been said at a particular window of time becomes much easier if what has been said before is known. If you need learning material, there are excellent Machine Learning and Deep Learning courses on Coursera.
Connectionist Temporal Classification
Earlier we saw how audio files are broken down into 10 ms chunks and each block represented by an array of features. We then feed each chunk to the network one by one and the network would predict, sometimes called emit, letters. There’s one problem though. When we speak, we don’t say out letters in fixed time durations. Letters are stretched in time as the image below shows.
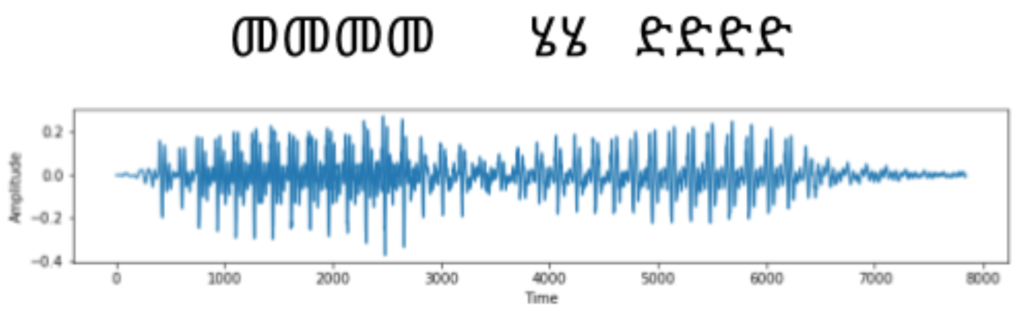
We solve it by Connectionist Temporal Classification (CTC). In CTC, all the መ’s shown in the image above would be collapsed into a single character, and similarly for “ሄ” and “ድ” characters. What if the word spoken was “መመከር” and we don’t want to collapse the two መ’s into a single “መ”, which would give the wrong prediction “መከር”? For this, CTC introduces a special blank character. Let’s call it B for short. If the network thinks another character was spoken, whether it’s the previous character repeated or a different one, then it emits B. It’s distinct from the space character which is emitted if there is a long silence, normally heard between words. All in all, the network predicts all Amharic characters in the training transcription, B and space.
What we really get during prediction is probabilities for each character. So we end up with a matrix showing probabilities for each character on each time step. Let’s see an example. Listen to the following clip.
I will go into detail about how I built the machine learning model itself. For now though, take a look at the predicted probabilities. Since the full prediction matrix is too big, I have removed predictions for most of the characters except the interesting ones and removed all time steps except the ones most relevant to the first word.
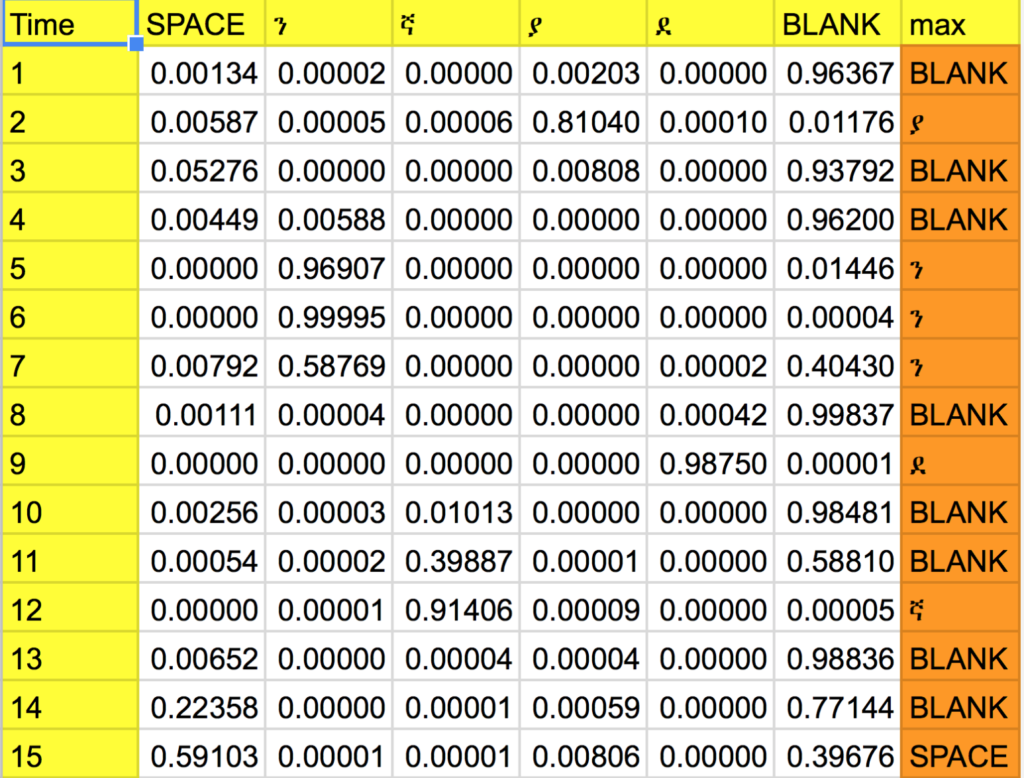
In the max column we simply take the character with the maximum probability in each time step (row). It’s called a greedy approach.
Although greedy approach worked just fine in our particular example, it’s not the ideal solution. For example “ያያB”, “ያBB”and”BያB” are three paths which all result in the same prediction “ያ” after collapsing. So what we really need is to find a more holistic probability which considers all the paths that would lead to the same transcription. For example, for the first time step if “ላ” turned out to have the highest probability, a greedy approach will simply pick “ላ” without comparing the overall probability of all paths that start with “ላ” with those that start with “ያ”.
The ideal solution would take the entire sequence of characters that could ever be predicted in the duration of the clip. Then for each it would find all the paths that lead to that particular sequence of characters. Finally, the probabilities for each paths are summed up. The result would be probabilities for each sequence of characters in the entire time step. We then simply pick up the character sequence with the maximum probability. This operation has exponential complexity. There are 224 characters in my setup. Let’s take a 5 second clip and assume we split each second into 100. We’re end up with 224^500 paths to process! It’s not feasible at all. So we do a beam search. Instead of considering all characters, we remove the ones that have too little probability to be considered. We also look ahead in shorter time steps instead of the entire clip.
To sum up, CTC allows us to take probabilities from the network and decode them into a sequence of characters.
Acoustic Model
We have pre-processed audio signals to get MFCC features, and worked out how network predictions can be decoded into letters. Now let’s see what happens in the middle. We need to associate audio signals, represented by MFCC features, with Amharic characters. This part is known as acoustic modelling.
Model 1
The first model I tried had one RNN layer with Gated Recurrent Unit (GRU) followed by normalization. Finally, there’s a softmax layer to output letter probabilities.
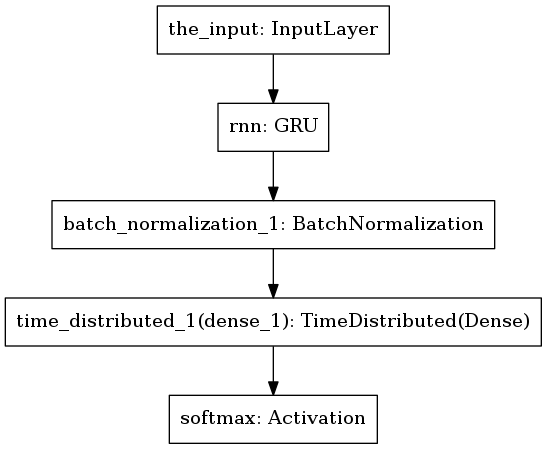
Predicted text was nowhere close to the truth. Here is a typical example.
Truth: ያንደኛ ደረጃ ትምህርታቸው ን ጐንደር ተ ም ረዋል
Predicted: ጌጭሹጭካጌካጐጭቋጭካቋካሶካዤካጪኰጪዊኰጪዊሩሸሩሸቋጪቋጌቼኮጼዛሙጪኰጣኰእኰላጼላጼኰጪህችህጪኰጪኰኩጼጪጧጽቀአእሸሄኬሄአሩህሄህጽጪሹጪሹጪዊአምአ’ዊሸሹራዊዚኙኩጯኩኬጃሹካጪካዊኰአዋኰሹይካጪኰጪሄሙኋሙኛጼጪኰጪኰጪኰጪቆቮሙ’አላሊላሊአሙአሙአሙሩዊዤካዤካቿዊፉዊዋዊዚኩጼዚዋሹአሹዋሙዋሙዋሹአቋዤኬሄርሸሩሸ’ሸቋጃቋጭቋጭጪጭቋካቋሄጭቋጭቋጭ
Model 2
In the second model I took inspiration from Baidu’s Deep Speech research. One of their improved architecture is Deep Speech 2. Although I haven’t exactly replicated their network, my aim was to have a network a bit similar to theirs. I put a convolutional layer followed by several GRU layers.
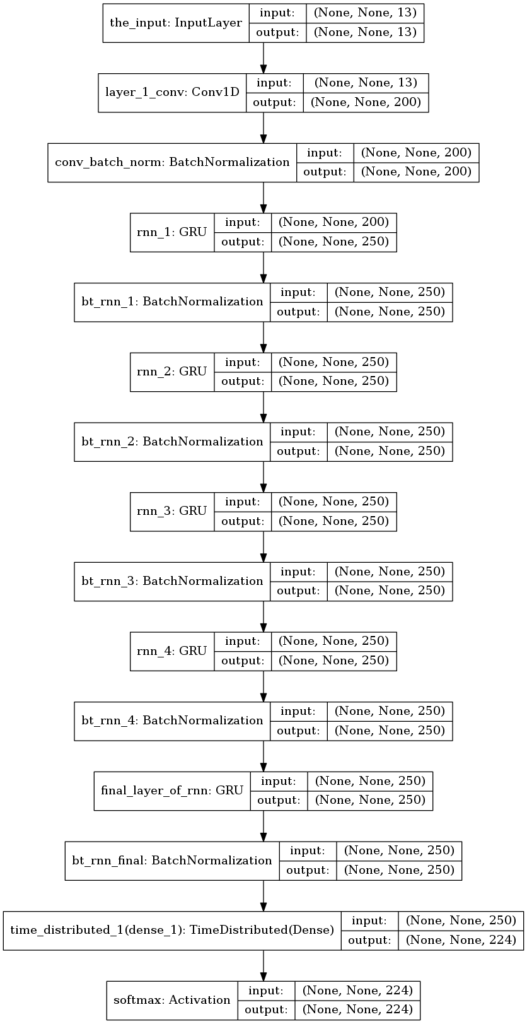
Due to the size of the network, I used GPU instances on Amazon AWS for faster experimentation then ended up running the final training on my laptop. My hardware was Intel i7 8 core CPU. Training consumed about 5 cores and took 3 days to do 40 epochs (rounds) through the data. Investing on GPU would be more appropriate although I feel there are other high priority tasks as I will discuss under Improvements section. Here is how the training history turned out.
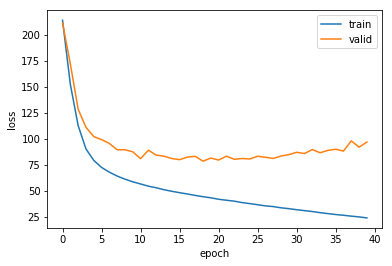
Since validation error increased from epoch 20 onwards, I recorded the model on epoch 22 and evaluated the predictions. Performance on training data was encouraging. Here are two examples.
Truth: ያንደኛ ደረጃ ትምህርታቸው ን ጐንደር ተ ም ረዋል
Predicted: ያንደኛ ደጃት ምርታቸው ቆንዳር ተምረዋል
Truth: ወሬው ን ወሬ ያደረጉ ምስጢረ ኞች ናቸው
Predicted: ወሬ ውድ ወሬ ያደጉ ምስጥረኞች ናቸው
Here is another example, this time on validation data (data not seen by the model before).
Truth: በ ብዛት ግን በ የ መንገዱ ዳር በ የ በረንዳ ው ላይ ም ለ ማደር በ መከልከላቸው ማይ ሀብ ሀብ የተባለ የ ከተማው ቆሻሻ ማጠራቀሚያ ቦታ የሚያድሩ መሆኑን ገልጠዋል
Predicted: ስክእ ብዛት ብንበ የ መንዱዳር በ የ በረን እና ላይን ን ብለ ማደር በ መከል ካ ላቸው ማ ራ ሀ በተባለከት ማቆሻሽ መተረቀ መያበጣ የሚ ያጡ መሆኑ ን ጋልተዋል
It’s far from perfect but it has achieved one of the first steps in machine learning, which is to have a model capable of fitting training data. Word Error Rate (WER) is one way of evaluating speech recognition models. You can find my analysis of that on github as well.
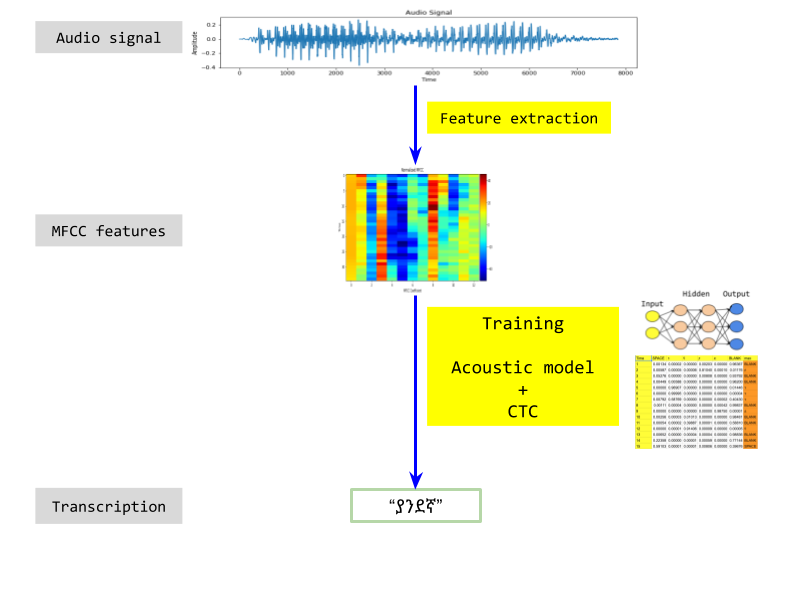
The full picture
To summarize, here is the full picture of my approach.
Improvements
Going forward, there are several interesting venues to build up on. Let me list a few in order of priority.
1. Data
3k hours of speech used to be considered sufficient for training. Big tech companies now use up to 100k hours and beefy hardware. Only 20 hours of data is available for Amharic. More data is needed with different speakers and text. Data can also be synthesized. For example an audio can be duplicated and background noise added on the duplicated data. It helps the model become robust on audio with noise.
2. Language Model
State of the art systems use DL together with a Language Model (LM). Wouldn’t it be nice to take the predicted text and pass it through a spell correction tool? LMs go even further. Let’s say the network is confused between “ተስፋ አለው” and “ተስፋ አለሁ”. It can well decide to predict “ተስፋ አለሁ” if it has the highest probability. A LM would be trained separately on Amharic corpus and no speech is involved. It will know that “ተስፋ አለው” is more probable than “ተስፋ አለሁ”. As opposed to a spell corrector which works after a bunch of words have been written, LM in speech recognition would have a tighter integration with the network. The network would predict probabilities based on speech, and the LM would help predict words. If you think about it, humans do something similar to hear speech as well. Ideally we wouldn’t use LM at all and the network would predict the most likely sequence of words by itself. This is called end-to-end learning and the final goal of deep learning researchers is to get to a point where no pre and post processing is required. The idea is to have the network do pre-processing using it’s initial layers and post processing using the final layers. Doing so requires much larger training data because we would be training the model not only as to how to translate speech utterances into characters, but also how people normally fit words together in that language. So it’s easier to train on textual data separately and then use trained LM model to aid the acoustic model.
3. Model
We have proved to ourselves that the model is capable of fitting training data given to it. The next step is to look into regularization to have a good validation accuracy. This problem can benefit from having more data as well. Different network architectures can be investigated too.
4. Features
As mentioned under Language Model, the goal is to have end-to-end training. And so we wouldn’t even need any pre-processing. Baidu 2 goes a step in this direction by using spectrogram features. There is also some research on using audio signals (the raw data) although it’s still in its infancy.