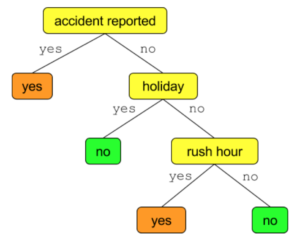
In the previous post I talked about Decision Trees. In this post I will talk about how to represent decision trees in SQL.
But first, why would you want to do that? There are Weka (a data mining tool), Scikit Learn (the mainstream machine learning library at the moment), H2O or Spark MLlib (both rooted in big data). However, there are several steps you have to take,
- Feed your data to the library/framework
- Train
- Persist the model
- Figure out the model’s API
- Bundle your model with your application together with any dependencies it may have
Every step is a hurdle against quick development and deployment. If you have your data in a SQL-like database, wouldn’t it be nice to just have a SQL that expresses a decision tree? If the trained model is a SQL string with no dependencies then steps 3 to 5 are no longer needed.
An example
A popular data for decision tree is the Iris dataset. It was first gathered in 1936 and has since been analysed in numerous research papers. Each row in the dataset represents a sample flower. There are three different species of the Iris flower and all of them are equally represented in the dataset (so there is 50 of each).

Here are the five columns,
- SepalLength
- SepalWidth
- PetalLength
- PetalWidth
- Name
What we want to do is learn from the data to give a decision tree that can take the first four columns as input and predict the species name. I wrote a small script that uses scikit to learn a decision tree from this data and translate the decision tree to a SQL.
There are plenty of tutorials on the web about using scikit. So I’ll just point you to my small script that outputs the SQL. It uses scikit to train a decision tree on the 150 rows, takes the decision tree and translates its to SQL. Here is what the result looks like,
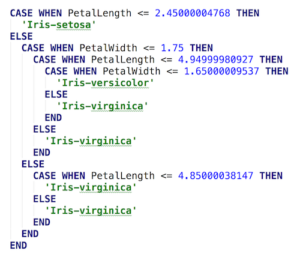
It’s beautiful 🙂 Let’s look at it in detail a bit. The first case shows the Iris Setosa species must have a very distinctive petal length. The second case shows that if petal length is ambiguous then petal width is used to narrow things down.
By the way, the example is not far fetched. An interesting and recent example is how a farmer used machine learning to automatically sort Cucumbers. You can read about it on Google’s blog.
Thoughts on big data
- If data is huge then a distributed solution becomes necessary.
- The final output after a lot of churning is still going to be a decision tree, which can be expressed as SQL.
- SQL can be ran not just on old relational databases, but on new ones too, such as Hive and MemSQL.
Final notes
Although NoSQL generated a lot of noise relational databases and SQL still kick ass. We will always deal with tabular data and SQL will remain a powerful language to express database operations. On the other hand, the further our data analysis tool live from our databases, the more mundane work there is to do. Machine learning doesn’t have to be all new technology. A simple SQL query could be just what you need.